

You’ll learn how to archive almost any information-rich site to create an offline version for yourself. The free, cross-platform command line utility called wget can download an entire website. The article will guide you through the whole process. I’ll start from scratch, then progress through detailed examples of cherry-picked settings to arrive at an excellent, post-processed archive. After reading this tutorial, it’ll be much less intimidating than it seems to be.
Why would you want to do this?
Contrary to popular belief, not everything online is there forever. Sites get shut down, censored, acquired, re-designed or just lost. This idea originates from the data hoarder community on Reddit, where the process of making archives for fun is nothing new. While we can’t predict or prevent a cataclysmic event of our favorite website, we can undoubtedly preserve them in their current form.
There are many possible uses and reasons why one might download an entire website. It does not matter if the target site is yours or not. On a side note, be careful about what you download. Perhaps you wish to conserve an era of a site with a particular design. Maybe you want to take an informative website with you to a place without internet. This method can ensure that a site stays with you even by the time you are a grandpa or a grandma. You could also host the now-static version of your website on Github Pages.
How does it work?
Wget will start from a specific URL and work to visit every link, recursing to infinite depths. It has the potential to crawl the entire site eventually. The way I set it up ensures that it’ll only download an entire website and not the whole internet – by accident. In other words, it’ll not wander off to external sites nor download anything from them. You’ll receive every asset like JS, CSS, and images. Of course, and all internal links will convert to relative links. The latter is vital to have a browsable offline copy, while excluded or external links remain unchanged.
Note that the archive is not a backup and you can’t restore your site from it. The described method uses front-end crawling, much like what a search engine does. It’ll only find pages to which is linked to by others. As a side effect, you’ll see the importance of using internal links on a site to connect pieces of content, to help robots crawl your site.
I’m aware that this is not strictly related to WordPress, but it works exceptionally well with blogs using this platform. The mere fact that a blogger is using some standard WordPress widgets in the sidebar (like the monthly archive or a tag cloud) helps bots tremendously.
Setting up wget on Windows
While the subculture that uses wget daily is heavily weighted towards Unix, using wget on Windows is a bit more unusual. If you try to look it up and blindly download it from its official site, you’ll get a bunch of source files and no .exe file. The average Windows user wants the binaries, therefore:
- Get the latest Windows version of wget, choose the last version zip and unpack it somewhere. I use a folder for portable software, as this does not require installation (yay!).
If you try to open the .exe file, likely nothing will happen, just a flash of the Command Prompt. I want to access this wget.exe by having an open Command Prompt already in the folder where I’ll download an entire website archive. It’s unpractical to move the .exe there and copy it to any other archive folder in the future, so I want it available system-wide. Therefore I ‘register’ it by adding it to the Environment Variables of Windows.
"C:\Windows\system32\rundll32.exe" sysdm.cpl,EditEnvironmentVariables- Hit Windows+R, paste the above line and hit Enter
- Under User variables find Path and click Edit…
- Click New and add the complete path to where you extracted wget.exe
- Click OK, OK to close everything
To verify it works hit Windows+R again and paste cmd /k "wget -V" – it should not say ‘wget’ is not recognized.

Configuring wget to download an entire website
Most of the settings have a short version, but I don’t intend to memorize these nor type them. The longer name is probably more meaningful and recognizable. I cherry-picked these particular settings from the comprehensive wget manual, so you don’t need to dive too deep as it’s a relatively long read. Check the official description of these settings if you wish, as here I only share my opinion and why I chose them. In the order of importance, here they are.
Settings to use
--mirror
This is a bundle of specific other settings, all you need to know that this is the magic word that enables infinite recursion crawling. Sounds fancy? Because it is! Without this, you can’t download an entire website, because you likely don’t have a list of every article.
--page-requisites
With this, wget downloads all assets the pages reference, such as CSS, JS, and images. It’s essential to use, or your archive will appear very broken.
--convert-links
This makes it possible to browse your archive locally. It affects every link that points to a page that gets downloaded.
--adjust-extension
Imagine that you went out of your way to download an entire website, only to end up with unusable data. Unless the files end in their natural extensions, you or your browser is unable to open them. Nowadays most links don’t include the .html suffix even though they should be .html files when downloaded. This setting helps you open the pages without hosting the archive on a server. A small caveat is that it tries to be smart to determine what kind of extension to use, and it’s not perfect. Unless you use the next setting, content sent via gzip might end up with a pretty unusable .gz extension.
--compression=auto
I’ve found that to work with gzip-compressed assets such as an SVG image sent by the server, this eliminates the chance of a download like logo.svg.gz which is almost impossible to load locally. Combine with the previous setting. Note that if you use Unix, this switch might be missing from your wget, even if you use the latest version. See more at How could compression be missing from my wget?
--reject-regex "/search|/rss"
Bots can get crazy when they reach the interactive parts of websites and find weird queries for search. You can reject any URL containing certain words to prevent certain parts of the site from being downloaded. Most likely you’ll only uncover what you should have dismissed after wget fails at least once. For me, it generated too long filenames, and the whole thing froze. While articles on a site have nice short URLs, a long query string in the URL can result in long file names. The regex here is “basic” POSIX regex, so I wouldn’t go overboard with the rules. Also, it’s somewhat hard to test with trial & error. One gotcha is that the pattern /search will even match a legitimate article with the URL yoursite.com/search-for-extraterrestrial-life or similar. If it’s a concern, then be more specific.
Optional settings to know about
--no-if-modified-since
I only include it as I’ve run into a server where for every request wget complained that I should use this. I don’t intend to re-run the process later on the same folder to catch up with the current site. Therefore, it doesn’t matter much how wget checks if files have changed on the server.
--no-check-certificate
It’s not mission critical to check SSL certificates. This prevents some headaches when you only care about downloading the entire site without being logged in.
--user-agent
--user-agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"Some hosts might detect that you use wget to download an entire website and block you outright. Spoofing the User Agent is nice to disguise this procedure as a regular Chrome user. If the site blocks your IP, the next step would be continuing things through a VPN and using multiple virtual machines to download stratified parts of the target site (ouch). You might want to check out --wait and --random-wait options if your server is smart, and you need to slow down and delay requests.
--restrict-file-names=windows
On Windows, this is automatically used to limit the characters of the archive files to Windows-safe ones. However, if you are running this on Unix, but plan to browse later on Windows, then you want to use this setting explicitly. Unix is more forgiving for special characters in file names.
--backup-converted
It’s worth mentioning, as it’ll keep an original copy of every file in which wget converted a link. This can almost double your archive and requires cleaning after you’re confident that everything is fine. I wouldn’t usually use it.
Opening the command prompt in the right place
You’ll need to run wget from a command prompt that is working with the folder in which you expect to download an entire website. There are multiple ways to achieve this, starting with the most standard way:
- You know the drill: Windows+R and write
cmdand hit Enter - Type
cd /d C:\archive folderwhere the/dswitch allows for changing drives and the latter is the path to the archive.
If you want to learn how cd works, type help cd to the prompt. On some configurations, it’s necessary to wrap the path in quotes if it has a space character.
Extra ways
- To do it in fewer steps: Windows+R then
cmd /k "cd /d C:\archive folder" - If you use Total Commander, open Commands menu > Run Command Shell
- Get an “Open command window here” entry in the context menu of File Explorer using a .reg file.
Running the download
Once I combine all the options, I have this monster. It could be expressed way more concisely with single letter options. However, I wanted it to be easy to modify while keeping the long names of the options so you can interpret what they are.
wget --mirror --page-requisites --convert-links --adjust-extension --compression=auto --reject-regex "/search|/rss" --no-if-modified-since --no-check-certificate --user-agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36" https://yoursite.comAll that’s left is to run this command to download an entire website. Tailor it to your needs: at least change the URL at the end of it. Be prepared that it can take hours, even days – depending on the size of the target site. And you don’t see the progress as it’s only possible to fathom the archive size in hindsight.
I’m not kidding when I warn about lots of tiny files.
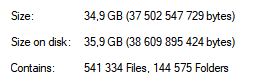
For large sites with tens or even hundreds of thousands of files, articles, you might want to save to an SSD until the process is complete, to prevent killing your HDD. They are better at handling many small files. I recommend a stable internet connection (preferably non-wireless) along with a computer that can achieve the necessary uptime. Nearing completion, you’ll see that wget is converting links in files. Something like:
Converted links in 35862 files in 187 seconds.After that, you should get back the command prompt with the input line. If it stops early, it’s advisable to adjust your settings and start over in an empty folder.
Post processing the archive
Unfortunately, no automated system is perfect, especially when your goal is to download an entire website. You might run into some smaller issues. Open an archived version of a page and compare it side by side with the live one. There shouldn’t be significant differences. I’m satisfied if all the text content is there with images. It’s much less of a concern whether dynamic parts work or not. Here I address the worst case scenario where images seem to be missing.
Modern sites use the srcset attribute and <picture> ... </picture> tag for loading responsive images. While wget is improved continuously, its capabilities lag behind the cutting-edge technologies of today’s web. While wget version 1.18 added srcset support, it doesn’t like the more exotic<picture> <source> <img> </picture> tag combo. This results in wget only finding the fallback image in the img tag, not in any of the source tags. It doesn’t download them nor does it touch their URL. A workaround for this is to mass search and replace (remove) these tags, so the fallback image can still appear.
- Get the latest grepWin – I recommend the portable version.
- Add the archive’s folder to Search in
- Choose Regex search and Search for:
<source media=".*"> - Add
*.htmlto File Names match: - Click Replace (you can verify it finds something with Search beforehand)
You can use grepWin like this to correct other repeated issues. One article can’t prepare you for everything nor teach you Regular Expressions (hint: there is nothing regular about them). Thus, this section merely gives you an idea of adjusting the results. The Windows approach falls short on advanced post-processing. There are better tools for mass text manipulation on Unix-like systems, like sed and the original grep.
A possible alternative without recursive download
In case you want to download a sizeable part of a site with every mentioned benefit but without recursive crawling, here is another solution. Wget can accept a list of links to fetch for offline use. How you come up with that list is up to you, but here is an idea.
Use Google Advanced Search in a particular way that identifies pages you like from the target site. An example search would be site:yoursite.com "About John Doe" which could return indexed posts written by that Author (if there is no on-site way to reach that list). This assumes there is an about this author box under the article. Temporarily changing Google search results page to show up to 100 results per page, combined with an extension like Copy Links for Chrome, you can quickly put together your list.
wget --input-file=links.txt --page-requisites --convert-links --adjust-extension --compression=auto --no-if-modified-since --no-check-certificate --user-agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"
I added --input-file=links.txt while dropping --mirror --reject-regex settings.
Closing thoughts
Now that you have some understanding of how to download an entire website, you might want to know how to handle such archive. Lots of tiny files are the death of many systems meaning it’ll be utterly slow to transfer, backup or virus scan it, especially if you don’t keep it on an SSD. Unless you want to browse the archive actively, I recommend compressing it. The main reason is not space requirements. Having the archive as a single big file or a series of larger files makes it more manageable. You can use RAR’s Store or Fastest Compression method to create a package quickly. Unless the content is mostly text, it might not benefit much from extra compression. The presence of a recovery record in a RAR archive (not added by default) helps in case of hardware failures such as bad sectors or other data corruption during storage or transfer.
Using your archive is rather easy, just open any HTML file and start browsing the site. External assets like social sharing buttons will still load from their original location. In case you are genuinely browsing offline, they’ll fail to load. Hopefully, they won’t hinder your experience too much.
Please understand that every server is different and what works on one, might be entirely wrong for the other. This is a starting point. There is a lot more to learn about archiving sites. Good luck with your data hoarding endeavors!






Comments are closed.